

Using a local SQLite database for state management is a quickly-evolving new approach, and over time we will see it become viable for more and more use cases. In this post, we look at the basics of using a synced SQLite database as a state management system.
Typical state management in React
With React[1], regardless of which state management framework is used, you typically have one-way data flow between state, actions and the view:
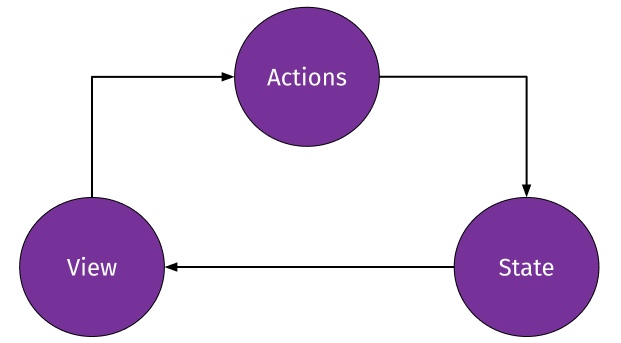
The view (the page or components) is rendered from the current state, and re-rendered whenever the state is updated. It can trigger actions (such as a button on-click), which update the state.
State management frameworks differ in how state is stored, how actions update the state, and how changes to state are detected and propagated back to the view.
Some frameworks like Redux require you to use immutable state, and each action creates a new “copy” of the app state.
Other frameworks like MobX let you work with plain JavaScript objects, and detect changes made to the properties directly.
Using a SQLite database to manage state
Here we describe a different approach: Using a SQLite database to manage state:
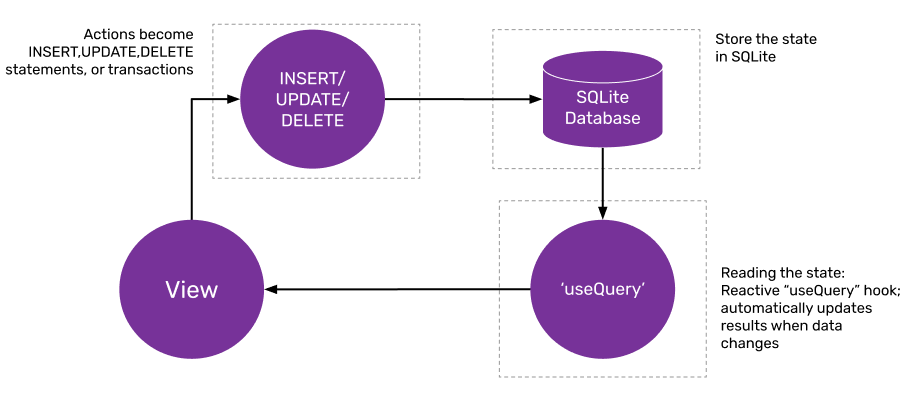
We store the application state in a SQLite database.
Actions become SQL queries — simple INSERT, UPDATE or DELETE statements, or more complex transactions.
Reading the state is done using a reactive [.inline-code-snippet]useQuery[.inline-code-snippet] hook[2], which automatically updates the results whenever the underlying data changes.
Now, we have the full power of SQLite available for our state management:
- State is automatically persisted across page reloads.
- The database handles change detection for us (more on this later).
- We can use plain SQL queries and views to filter and transform the state as we like.
- We can use fast local queries to load any data from any component.
Example: To-do list / task list app
As an example, let’s consider a “To-Do List” app that manages lists of tasks. We’re showing lists on the left, and tasks in the selected list on the right. The lists on the left include a counter of pending and completed tasks for each list, which should be updated as soon as any task is toggled.
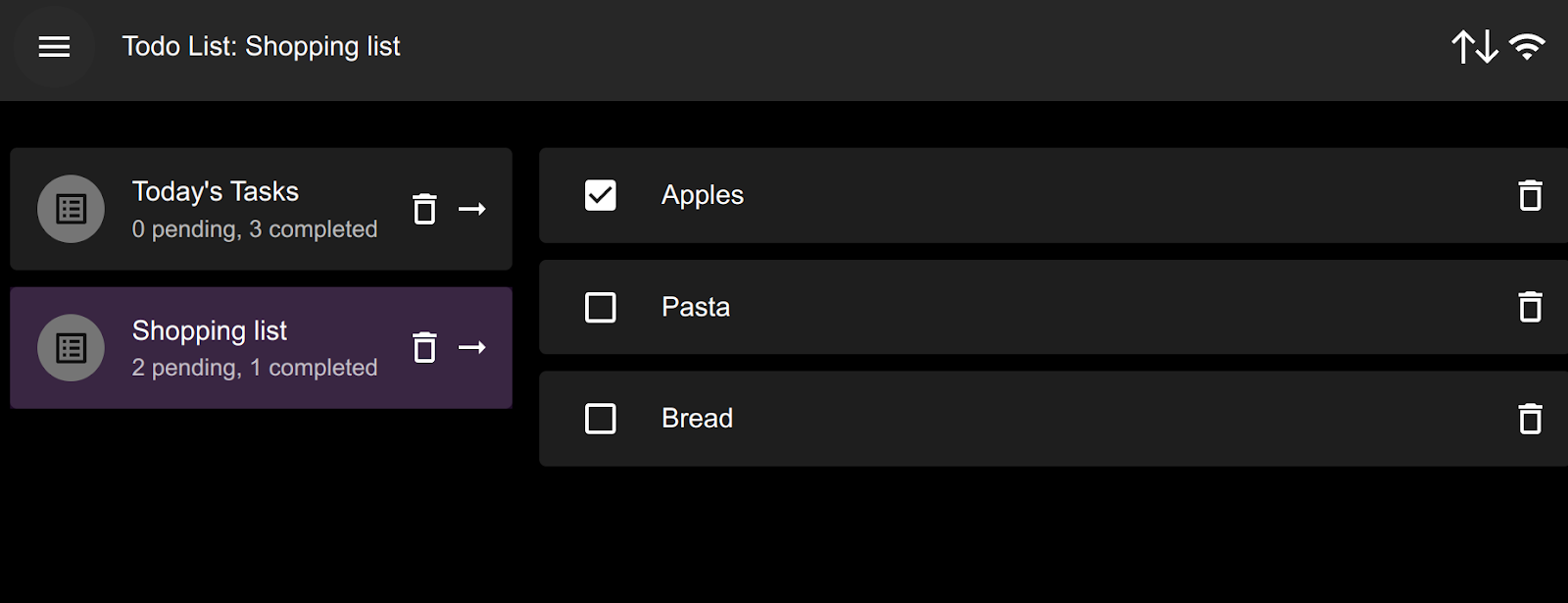
To create, delete or toggle tasks, we use simple SQL statements:
Our tasks query uses a simple [.inline-code-snippet]SELECT[.inline-code-snippet] statement with a [.inline-code-snippet]WHERE[.inline-code-snippet] clause, using the reactive [.inline-code-snippet]useQuery[.inline-code-snippet] hook mentioned above, which automatically updates the results whenever the underlying data changes.
Our lists query looks like this: (because we have the power of SQL, we can do things like subqueries and aggregations such as counting)
That’s all there is to it! Whenever a task is added, removed or toggled, the tasks and lists components are automatically re-rendered with the latest state.
useQuery hook
The [.inline-code-snippet]usePowerSyncWatchedQuery[.inline-code-snippet] hook[3] in the examples above is at the core of what makes this possible. Without it, we’d need to keep track of when queries are stale and need to be rerun, which could increase the state management complexity quickly. While it’s not directly part of SQLite, it is built on top of functionality that SQLite already includes:
- SQLite update hook: This fires a notification whenever a row is inserted, updated or deleted. While it provides the affected row ID, we only keep track of changed tables in our implementation.
- [.inline-code-snippet]EXPLAIN[.inline-code-snippet]: Given a query, this tells us which tables are read to produce the results. Unlike custom query parsing, this works with anything from a simple [.inline-code-snippet]SELECT[.inline-code-snippet] statement to complex joins, subqueries, views or common table expressions.
Combining those two, we rerun a query whenever data in one or more of the underlying tables have changed, and it works with practically any SQLite query.
It’s worth noting that this implementation does more work than is strictly required. In our example above, the tasks query will be rerun even if only tasks in a different list are modified. In practice, SQLite is so fast that it doesn’t matter for most use cases, and we get large benefits from the simplicity and flexibility of this approach.
Typed queries using Kysely
In the above examples we used plain SQL, which should work for developers already familiar with it. However, one disadvantage is that it doesn’t give us any type info for auto-complete or build-time error checking. To handle that, we can use the Kysely query builder to get typed queries and results:[4]
This is slightly more verbose in some cases, but gives us full TypeScript type checking for the query parameters and results.
Where to use queries for state
We generally recommend using queries higher up in the component hierarchy, and passing down the results as properties to components lower down. This allows us to efficiently load data for multiple components in a single query. In our example of task lists above, we use a single query to load all lists and their associated task counts, instead of an individual query for each list.
For transient local component state, such as the name of a new task as the user is typing it, React’s [.inline-code-snippet]useState[.inline-code-snippet] is typically more applicable. Once the user “saves” the task, we can save it to the database.
For navigation state, such as the current page or the currently-selected list, route properties (for example in the browser URL) are more applicable.
For transient global state, we could use a temporary database. Alternatively, React’s [.inline-code-snippet]useContext[.inline-code-snippet] or minimal usage of state management frameworks would also work for this. We can expect this to be a very small part of typical applications, once all persisted state is in the database.
Synchronizing with server-side state
So far in the examples above, we’ve worked with only a client-side database: There was no consideration of server-side state.
Writing a custom solution to keep the database in sync with a server is possible, but we would not recommend it. However, you don’t need to — there are multiple off-the-shelf solutions available to keep the SQLite database on the client in sync with a database on your server.
Using a sync layer such as PowerSync, ElectricSQL or CR-SQLite/Vulcan helps keep the client and server in sync automatically, and this has great advantages:
- No individual API requests needed to read data.
- No worrying about caching and cache invalidation — data is updated automatically.
- The app/site works fully offline.
Loading states and waterfalls
Due to the asynchronous nature of database queries, there can be a “flicker” on the first render of a component — it renders once before the results are available, then again after loading the results.
Moreover, when multiple components in a hierarchy each load their state, it can lead to a “waterfall” in rendering, which can introduce significant latency in apps that fetch data from an API over the network. See this post for a more in-depth discussion of the problem. Generally, this is called “fetch on render”, and is not recommended for loading data from a server.
When loading data from a local database, individual queries typically take less than a millisecond to complete, and we can run dozens of queries sequentially between two rendering frames. This significantly reduces the waterfall problem, since the delays introduced by queries are almost insignificant. However, there can still be “flicker”.
React <Suspense> offers a nice solution — with very minor code changes, we can render a fallback component such as a loader spinner while the queries are still loading. Adding React [.inline-code-snippet]startTransition[.inline-code-snippet] or [.inline-code-snippet]useTransition[.inline-code-snippet] will instead let React keep the current components until the queries have loaded, before rendering the new components. This is often just for a single frame, giving the appearance of the state loading instantly.
A future post will further dive into the details of Suspense. Implementing Suspense support for [.inline-code-snippet]usePowerSyncWatchedQuery[.inline-code-snippet] is currently in progress, and we already have a pull request open with a proof of concept.
Conclusion
Using SQLite for state management is a new approach and there is more work required to cover more use cases, higher data volumes, low-latency rendering and performance in general. But even so, it already works quite well for a large share of use cases, and several developers have started observing that it’s a nice benefit to a local-first architecture.
We are going to see a lot of new tooling around using a local-first paradigm for state management in the coming months, and over time, local-first state management may gradually start displacing use of existing state management frameworks.
Talk at LoFi Community
This blog post was also the topic of a talk given by Conrad (co-founder of PowerSync) at the Local-First (“LoFi”) Web Development community meetup #13. You can see the talk here:
Footnotes
[1] In this post we focus on React, but the same principles will apply to most other frameworks.
[2] In other frameworks than React, you would use the equivalent to this hook, for example [.inline-code-snippet]useQuery[.inline-code-snippet] might be a watch/subscribe API instead.
[3] The example code in this post is written for PowerSync, but the same concepts apply to other solutions.
ElectricSQL has [.inline-code-snippet]useLiveQuery[.inline-code-snippet]. It parses the query in JavaScript to get the underlying tables, which imposes some limitations (e.g. it cannot handle views), but will cater for the majority of queries.
CR-SQLite/Vulcan has [.inline-code-snippet]useQuery[.inline-code-snippet]. It uses the SQLite tables_used function to get the underlying tables for the query. This is similar to [.inline-code-snippet]EXPLAIN[.inline-code-snippet] with a more stable API, but is not available in many SQLite builds by default (has to be enabled using a compiler flag).
[4] We are currently working on enabling [.inline-code-snippet]usePowerSyncWatchedQuery[.inline-code-snippet] to work with Kysely. We previously released an initial Kysely integration.