

Create a free PowerSync account or read our Supabase integration guide to get started.
Offline has been a Supabase deal-breaker for many
Supabase launched in January 2020. Later that same year, users asked for offline support in what has become not only the most upvoted but also the most commented on GitHub discussion in the Supabase org.
For many developers exploring Supabase as an alternative to Firebase, offline support felt like it should be a solved problem. Firebase’s Cloud Firestore was released just over a year earlier and seemed to handle the basics of offline support with its automatic caching capabilities. The comments left by some developers illustrate the point:

The challenge is that a true offline-first architecture is a hard problem to solve and without a easy to use solution for Supabase, many developers have had to stick with Firebase and it’s automatic caching (which only solves part of the offline problem — more on that later).
Why is offline so important?
Why are developers clamoring for offline when internet connectivity is abundant? In short, our hyper-connected world has led users to expect apps that are always available and feel instant to use.
Users want apps that are always available
Cloud software is the modern default. Users are now so used to being connected they can be forgiven for not anticipating they might be offline. But we haven’t arrived at guaranteed connectivity yet.
Take a few examples:
- A candidate waiting for an interview wants to revise notes while in a cafe with spotty Wi-Fi.
- A construction manager wants to update their project plan at an on-site office with an ISP outage.
- A mom wants to double check her son’s medication regimen on an overnight flight.
We can expect these users to instinctually open an app on their phone or laptop and attempt to view or update data, only to run into spinners and error messages. Instead of being frustrated with the limits of internet infrastructure, in reality they often blame the app itself.
The good news is that offline-first architectures can give users the behavior they want even when they are offline. These scenarios may seem like edge cases, but as your user base grows, so will the number of users that find themselves trying to access your app while unexpectedly offline.
That’s not to say that everything needs to work offline — users have learnt that some things require an internet connection. But in many cases, the expectation is that important data and functionality in an app should always be available without forethought (requiring the user to select and download certain data before going offline is not sufficiently user-friendly)
Users want apps that feel instant to use
Fiber optic cables and the growth of technologies such as CDNs have all but eliminated delays in accessing data over the internet. That’s not the only thing: users also want to know that they’re looking at the latest data. This emergent expectation that apps should feel instant to use results in three requirements for developers:
- When online, the UI should always reflect the latest data.
- The most important data should be immediately available (zero latency).
- When offline, data updates made by the user should be applied optimistically, so their UI shows their update even if that update must still be reconciled with the central database when the user goes online again.
Point 1 can be solved by real-time streaming of data changes. An up-to-date local database can solve point 2, practically eliminating latency since the data is available on device. Point 3 would be solved if that database keeps local data updates in a queue that can be rolled back if the server rejects a user update.
Why true offline-first and not just caching?
Many Firebase users are satisfied with how the caching functionality of Cloud Firestore caters for basic offline scenarios. So, is an offline-first approach really necessary? Yes. Some fundamental limitations of caching make it unable to provide the always available experience of true offline-first.
Reads and mutations are limited to cached data
For data to be read while a user is offline, it needs to be available on the user device. This means it must have been downloaded into the local cache back when the user was online. Data is typically downloaded and cached as users navigate through app pages, query data, or, in some cases, explicitly select data they want to have access to offline. If a user didn’t download the data, it would not be available in the cache.
How about forcing a download of all data when a user initially accesses the app? While this is a possibility, caches are typically not indexed and generally don’t perform as well as a local database (Google also advises against this). Caching is simply not designed for this.
As with reads, you can only perform updates to data already in the cache. A user who, say, wants to update all team member schedules but only accessed team members from one region while online, will not be able to access the schedules of team members outside of that region while offline.
With offline-first, all data relevant to a specific user is persisted on their device in a local database. This means that users have full CRUD capabilities even on data that they’ve never tried to access before.
Caches may include stale data even if users were recently online
Because data stored in the cache typically needs to be redownloaded to be updated with the latest data from the server, different cached data can reflect different states. For example: a physician wants to update a patient’s chart on their app while offline. If they last accessed that chart a week ago, and since then an assistant updated chart data from a different device, that physician will not see the updated data but rather the stale data that is still stored in their cache — even if they recently accessed their app but didn’t redownload that specific patient’s chart.
Offline-first with server reconciliation and automatic sync keeps the full local database consistent with the server up to the point where the user goes offline. This means the physician in the example above will see the changes made by their assistant, even if they didn’t access that specific patient’s chart since their assistant updated it.
Caches are constantly cleared
Data previously downloaded may no longer be in the cache. Caching keeps a local copy of data that has been viewed or otherwise downloaded by the user. Since the user could theoretically view or download an infinite amount of data, the cache needs to make sure it always has space available for new data.
It does this by purging data, typically through a Least Recently Used (LRU) strategy. However, this strategy could undermine offline capability: say a health inspector visits restaurants monthly, and one of those restaurants is in an area without network connectivity. If their cache generally fills up after about a month’s use of their app, data from their previous inspection would be purged just as they are making their follow-up trip and would be unavailable.
Offline-first with data scoping (or “sync rules”) allows developers to define what data should be stored on a user’s device. That data is then persisted indefinitely. Local databases can also typically store a lot more data while remaining performant when compared to caches.
Caches create a secondary source of data which can get complicated
Since apps with caches are designed to work “online-first”, they typically first attempt to get new data from the server and only fall back on cache data after that call fails.
Some single-use callbacks (like [.inline-code-snippet]get()[.inline-code-snippet] callbacks when working with Firebase), may require first trying to retrieve the server version of data and return the cached version only after that request times out. This becomes especially tricky with intermittent connectivity, where the server eventually responds but takes a long time – making the app feel slow to use.
With offline-first, the local database is treated as the primary data source for the app. Queries and updates can happen instantly against the local database. The sync system takes care of the rest.
The bottom line: Caching is not good enough
These limitations are well-known — precisely because caching approaches have been designed to work in an online-first paradigm, as a fallback for the edge case that users are offline.
Our view is different: while being offline may be an edge case for an individual user, the typical user now expects apps that are always available. Apps should be designed with this in mind.
Where existing solutions for Supabase fall short
We reached out to developers using Supabase to hear why they don’t use currently available solutions. Two reasons stand out:
Too much backend development required
For many developers, the key value of Supabase is that it eliminates the complexity of building a backend. Supabase frees up mental bandwidth for developers to focus on app development. Supabase users don’t want to spend time on backend plumbing.
It figures that those developers prefer approaches that do not require significant backend work. Client-side offline database frameworks like RxDB and WatermelonDB provide impressive client SDKs, but require developers to build non-trivial backend functionality to support their particular way of syncing data.
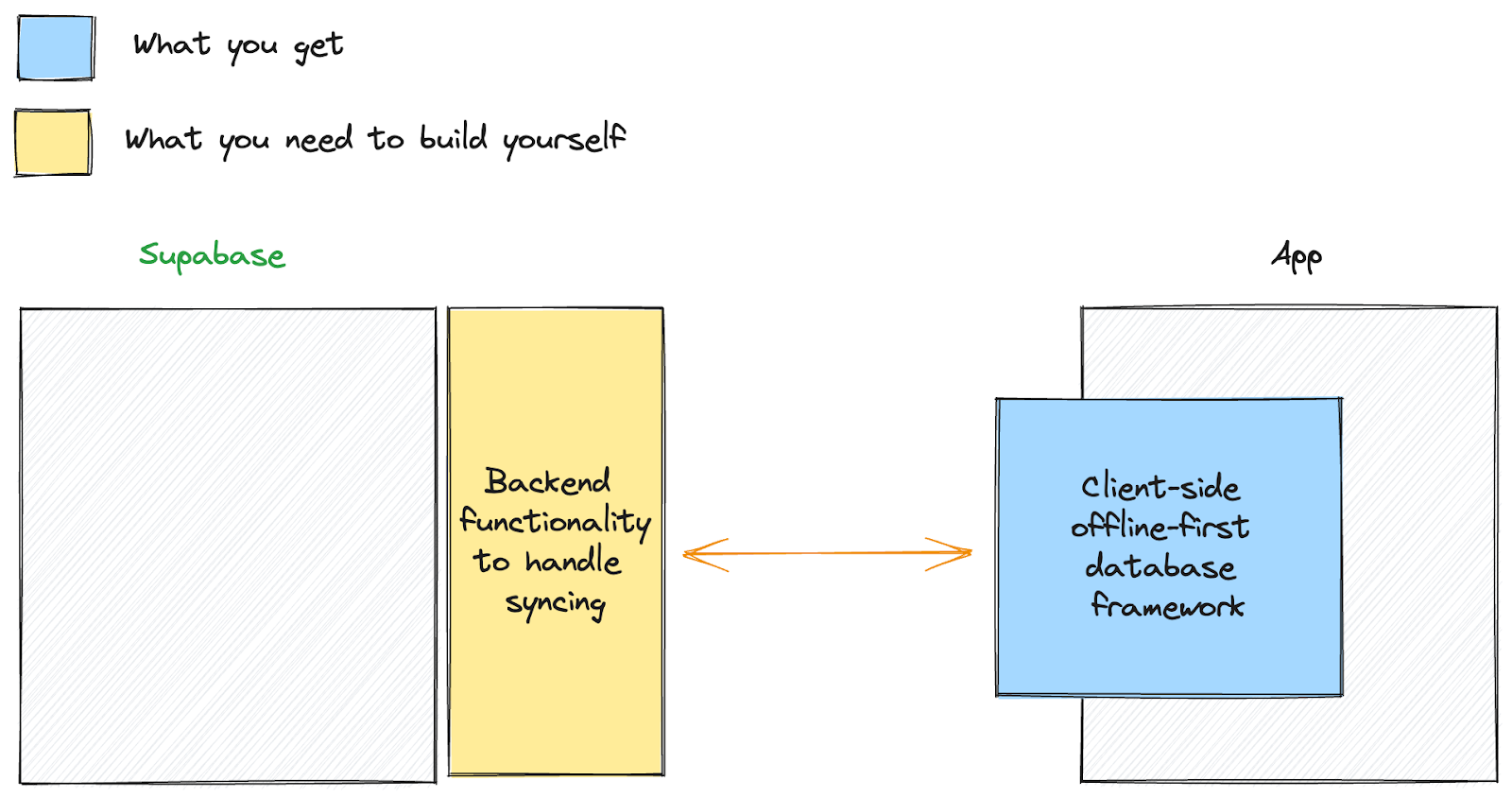
To their credit, both have great documentation on what needs to be done. Unfortunately, the fact remains that developers are responsible for building and maintaining the backend side of the equation.
Flutter support
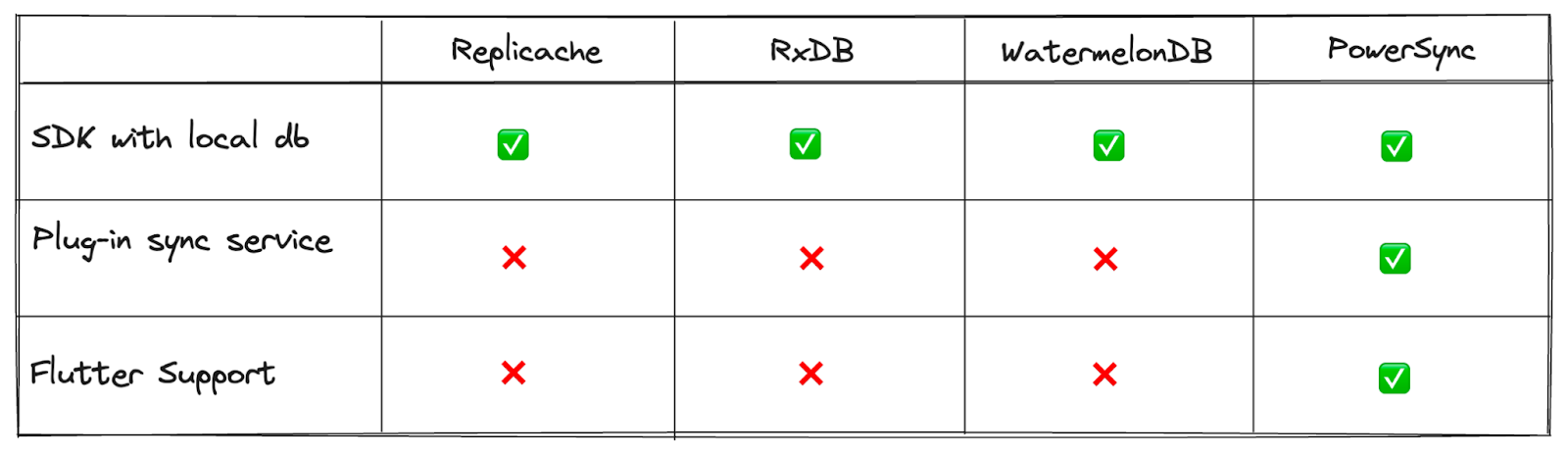
No existing solution supports Flutter. Replicache, for example, focusses on web apps. Since mobile users are most likely to experience spotty connectivity, and Flutter seems to be the most used mobile framework with Supabase, lack of Flutter support is an obvious gap.
Comparison Table

What PowerSync provides
PowerSync provides a plug-and-play client SDK and an integrated cloud sync service that plugs into Supabase. This means you get a complete offline-first architecture for Supabase (with robust consistency properties) out of the box.
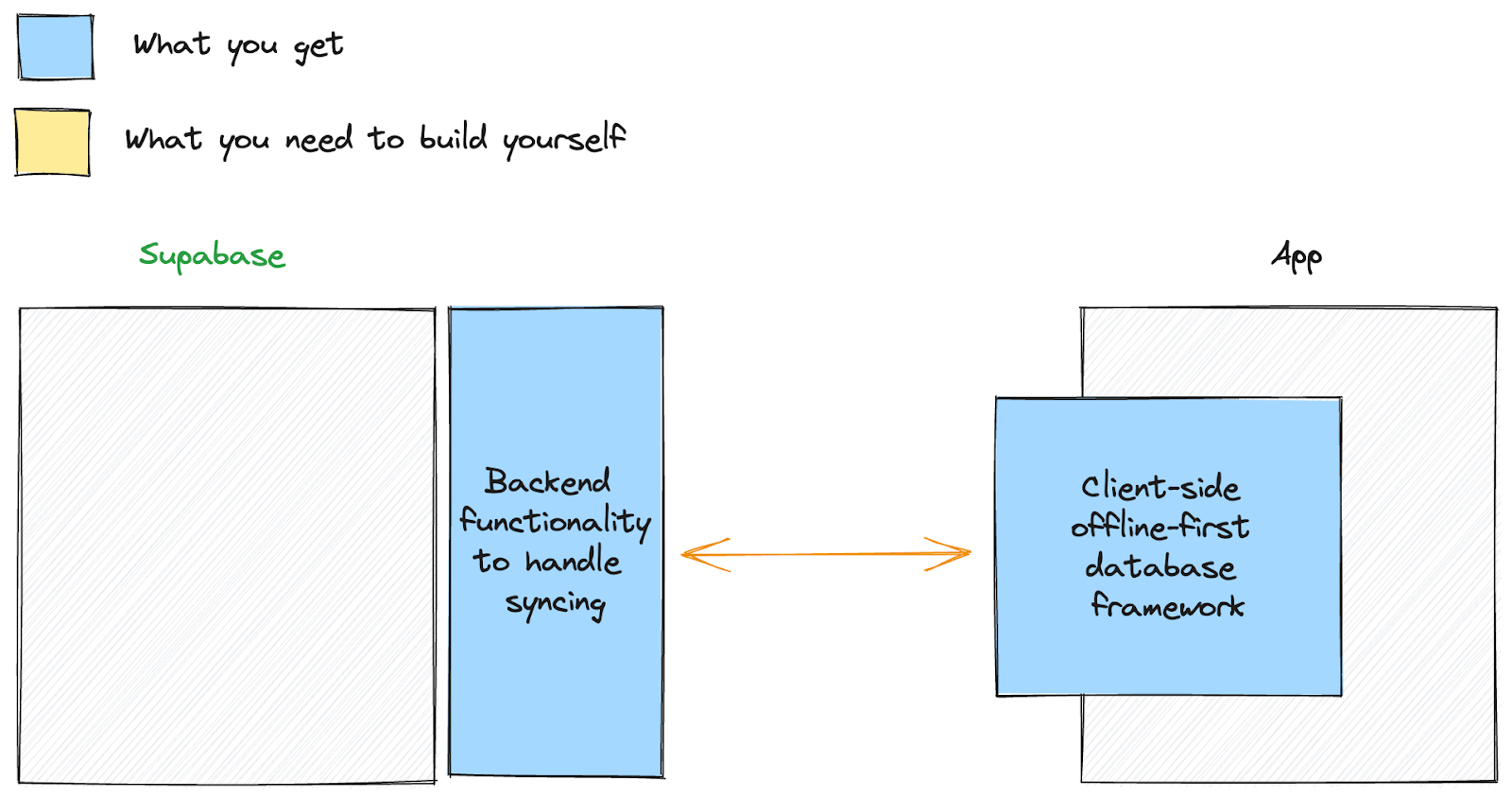
What does this sync service do?
Supabase CEO Paul Copplestone described what he sees as the right way for Supabase to support offline:
“...the right way to do offline would be to have a full, timestamped history of every single event that happened in your database. That way, when a client goes offline we can have the client say "give me every update between XX and YY timestamps". This is similar to how Watermelon works, but Watermelon requires you to implement an "updated_at" column in every table.”
“How can we achieve this without you needing to add this column to every table? We'd need to store the Write Ahead Log for your database, and then expose it via an endpoint. As you can imagine, this is a lot of data and there are no good off-the-shelf tools to do this. We also need to figure out how this approach works with RLS which adds some complexity.”
kiwicopple on Github, June 2023
PowerSync does exactly what Paul describes in the quote above:
The PowerSync service reads the Write Ahead Log (WAL) of your Supabase Postgres database and stores a version of it. It exposes that via an endpoint that the PowerSync SDK communicates with to sync data between server and client (we also figured out how to make this work with RLS).
And we went even further, by building:
- A robust consistency model with automatic integrity checks so the client can guarantee it’s working with a consistent set of data.
- A data scoping system so that the developer can define which users should sync which subset of the overall Postgres data based on declarative rules.
How PowerSync works
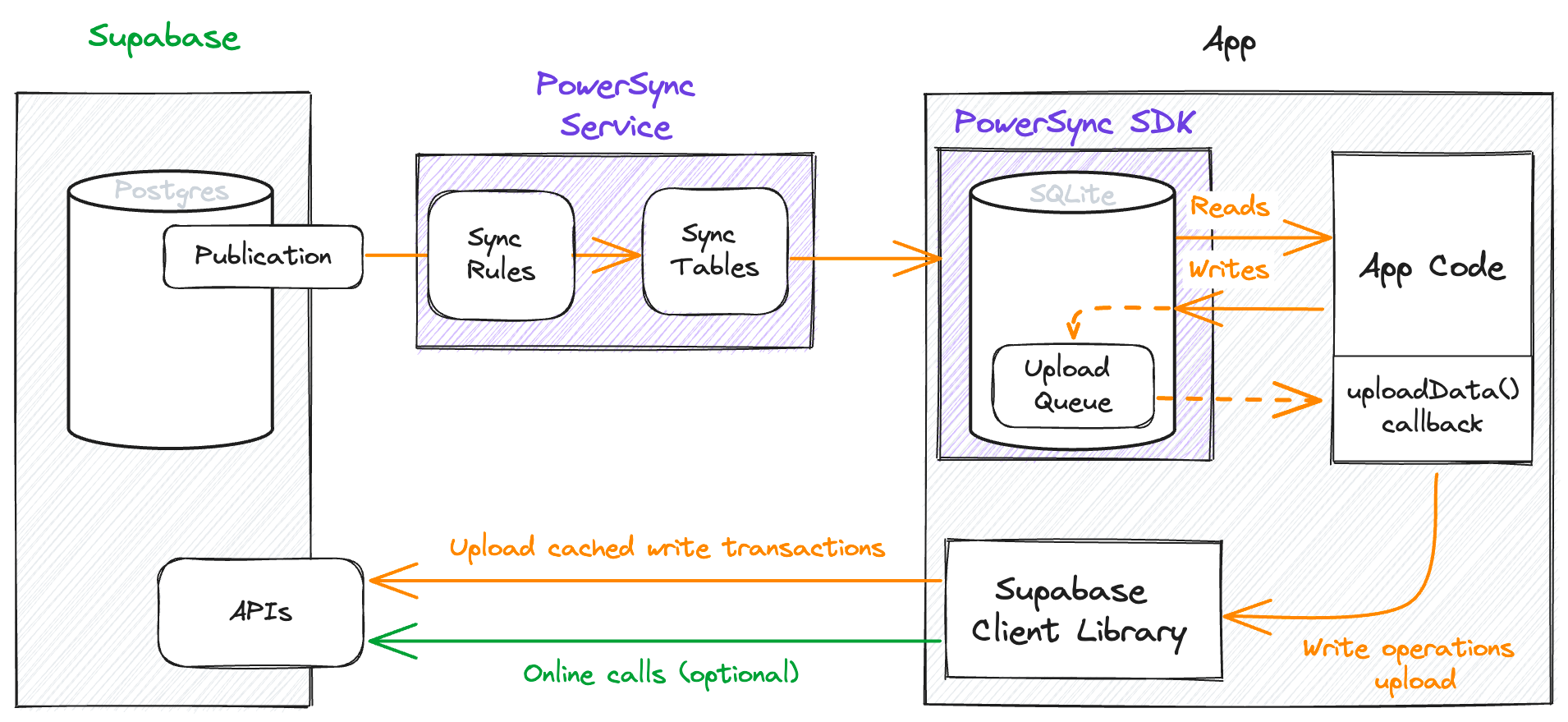
Used in conjunction with Supabase, PowerSync enables developers to build apps that are resilient to poor network conditions and have highly responsive frontends.
- The PowerSync service reads from a Publication of your Postgres WAL according to sync rules: declarative rules that, together with RLS, determine which data gets synced to which users.
- The PowerSync service maintains a set of live data views based on your sync rules – allowing the PowerSync SDK to sync a real-time stream of scoped data updates to a local database, ensuring users have access to the latest data when they’re online.
- App reads and writes happen directly against the local database: an embedded SQLite database managed by the PowerSync SDK.
- Local writes are additionally held in an upload queue until they’re sent to the Supabase database via the Supabase client library, through the PowerSync uploadData() callback function.
- Any online network calls can happen as they normally would through the Supabase client library.
Features
- offline-first architecture (app developers can work with the local database instead of an API).
- real-time data streaming to keep the local database up-to-date when the user is online.
- data scoping through sync rules (set rules defining which data should sync to which users).
- strong consistency (the strongest consistency possible in a distributed system: causal+ consistency).
Flutter support
PowerSync has a Flutter SDK.
Comparison Table
Now available
Our Supabase integration is now available! The best place to get started is with our integration guide.
PowerSync is free for all new users while we're in beta, and our planned pricing plans are available here. We also intend to release an open source version that can be self-hosted in the near future.
PowerSync is designed to be framework agnostic, with current support for Web, React Native, Flutter and Kotlin. Support for Swift is on the way.
We’d love to get your feedback! Join our Discord to chat about PowerSync and Supabase.